|
I am currently a senior research scientist at Waabi. I obtained my Ph.D in CS at UT Austin, under the supervision of Prof. Philipp Krähenbühl . During this time, I interned at Waymo, working on multi-agent behavior prediction. Before that, I studied at UC Berkeley majoring in Computer Science and Applied Mathematics, where I worked with Prof. Pulkit Agrawal, Prof. Deepak Pathak, Prof. Sergey Levine, Prof. Pieter Abbeel, and Prof. Jitendra Malik, working on robot manipulation. |

|
|
My research interests lie in robotics, computer vision and machine learning including reinforcement learning. I also work on autonomous driving.
|
|
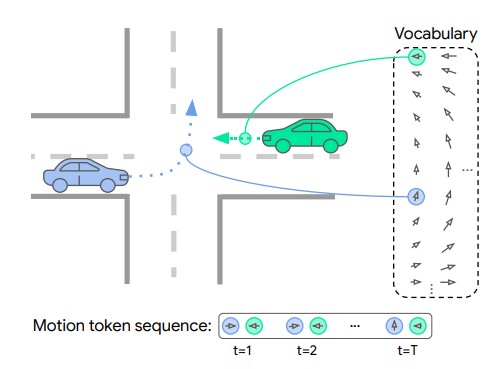
Ari Seff, Brian Cera, Dian Chen, Aurick Zhou, Nigamaa Nayakanti, Khaled S. Refaat, Rami Al-Rfou Benjamin Sapp International Conference on Computer Vision (ICCV), 2023 arxiv We present MotionLM, a behavior predictor that represent continuous trajectories as sequences of discrete motion tokens. MotionLM casts multi-agent motion prediction as a language modeling task over this domain. |
|
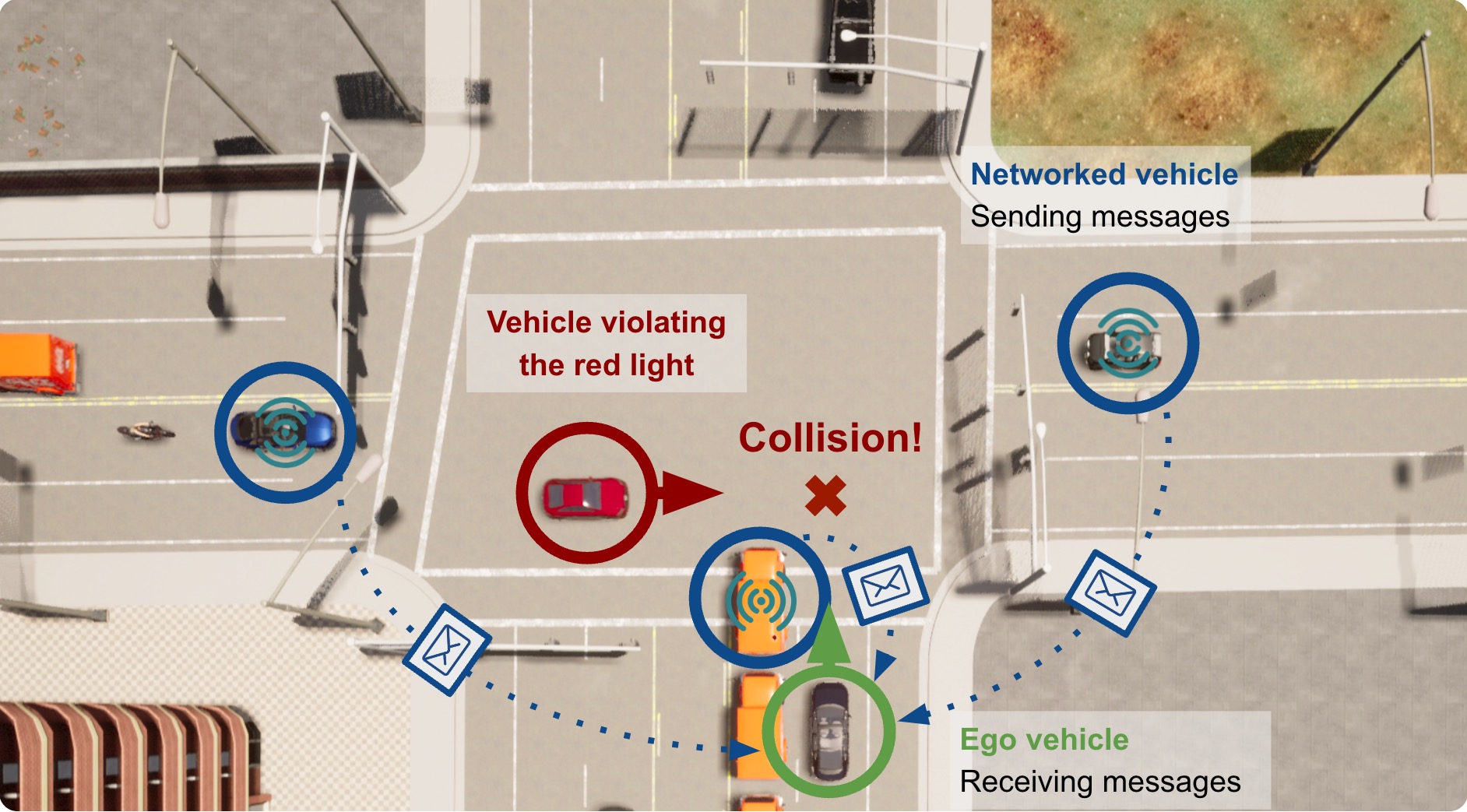
Jiaxun Cui, Hang Qiu, Dian Chen, Peter Stone, Yuke Zhu Conference on Computer Vision and Pattern Recognition (CVPR), 2022 website / code / arxiv We introduce COOPERNAUT, an end-to-end learning model that uses cross-vehicle perception for vision-based cooperative driving. Our model encodes LiDAR information into compact point-based representations that can be transmitted as messages between vehicles via realistic wireless channels. |
|
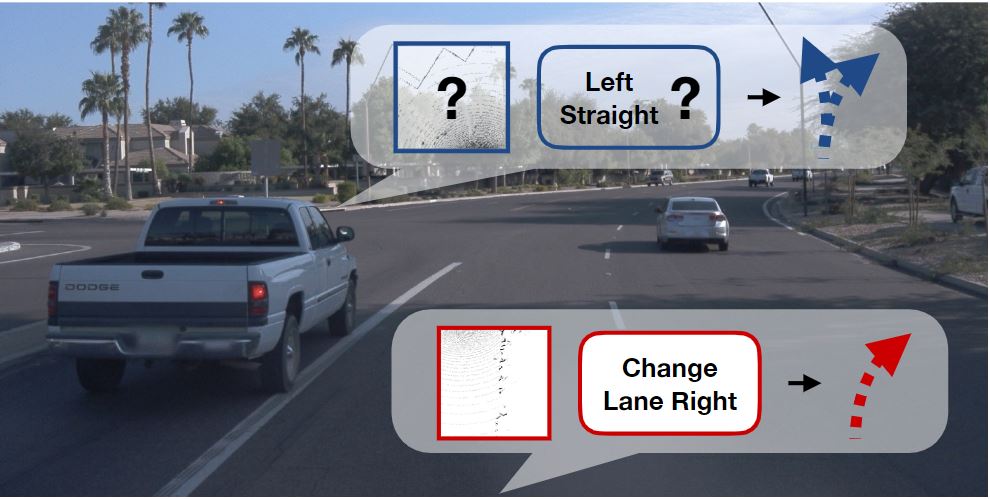
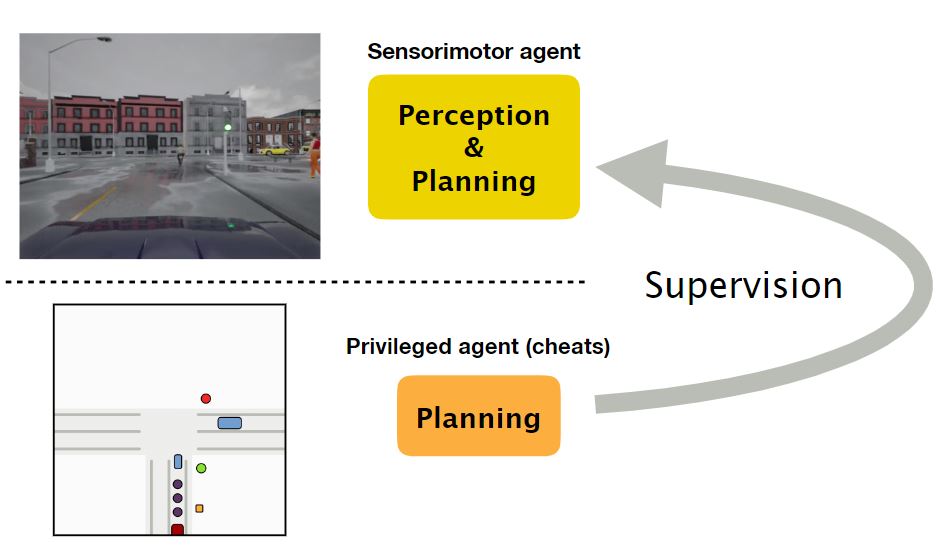
Dian Chen, Philipp Krähenbühl Conference on Computer Vision and Pattern Recognition (CVPR), 2022 Winner of 2021 CARLA AD Challenge website / code / arxiv We present LAV, a mapless, learning-based end-to-end driving system. LAV takes as input multi-modal sensor readings and learns from all nearby vehicles in the scene for both perception and planning. At test time, LAV predicts multi-modal future trajectories for all detected vehicles, including the ego-vehicle. Our system outperforms all prior methods on the public CARLA Leaderboard by a wide margin, improving driving score by 25 and route completion rate by 24 points. |
|
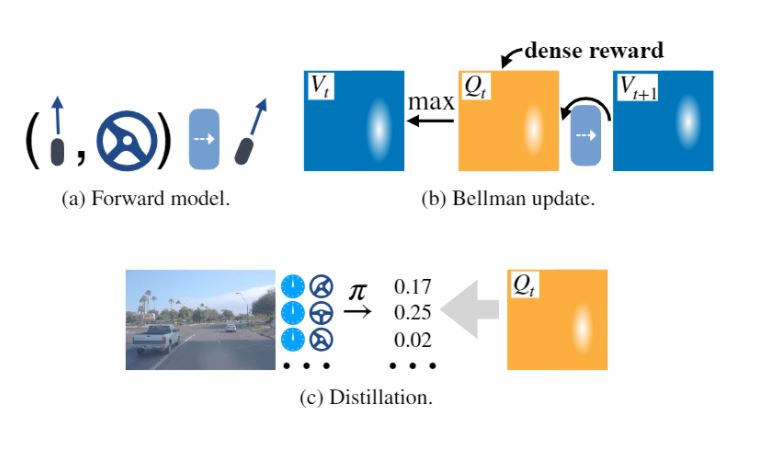
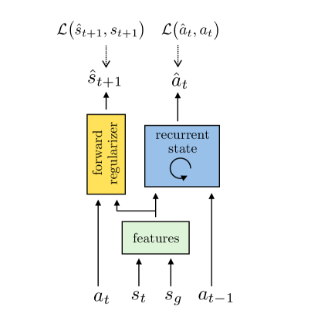
Dian Chen, Vladlen Koltun, Philipp Krähenbühl (Oral Presentation) International Conference on Computer Vision (ICCV), 2021 website / code / video / arxiv We present a model-based RL method for autonomous driving and navigation tasks. The world model is factorized into a passively moving environment, and a compact ego component. Our method significantly simplifies reinforcement learning. It ranks first on the CARLA leaderboard, and outperforms state-of-the-art imitation learning and model-free reinforcement learning on driving tasks. It is also an order of magnitude more sample efficient than model-free RL on the navigation games in the ProcGen benchmark. |
|
Dian Chen, Brady Zhou, Vladlen Koltun, Philipp Krähenbühl Conference on Robot Learning (CoRL), 2019 website / code / video / arxiv We present a two-stage imitation learning method for vision-based driving. Our approach achieves 100% success rate on all tasks in the original CARLA benchmark, sets a new record on the NoCrash benchmark, and reduces the frequency of infractions by an order of magnitude compared to the prior state of the art. |
|
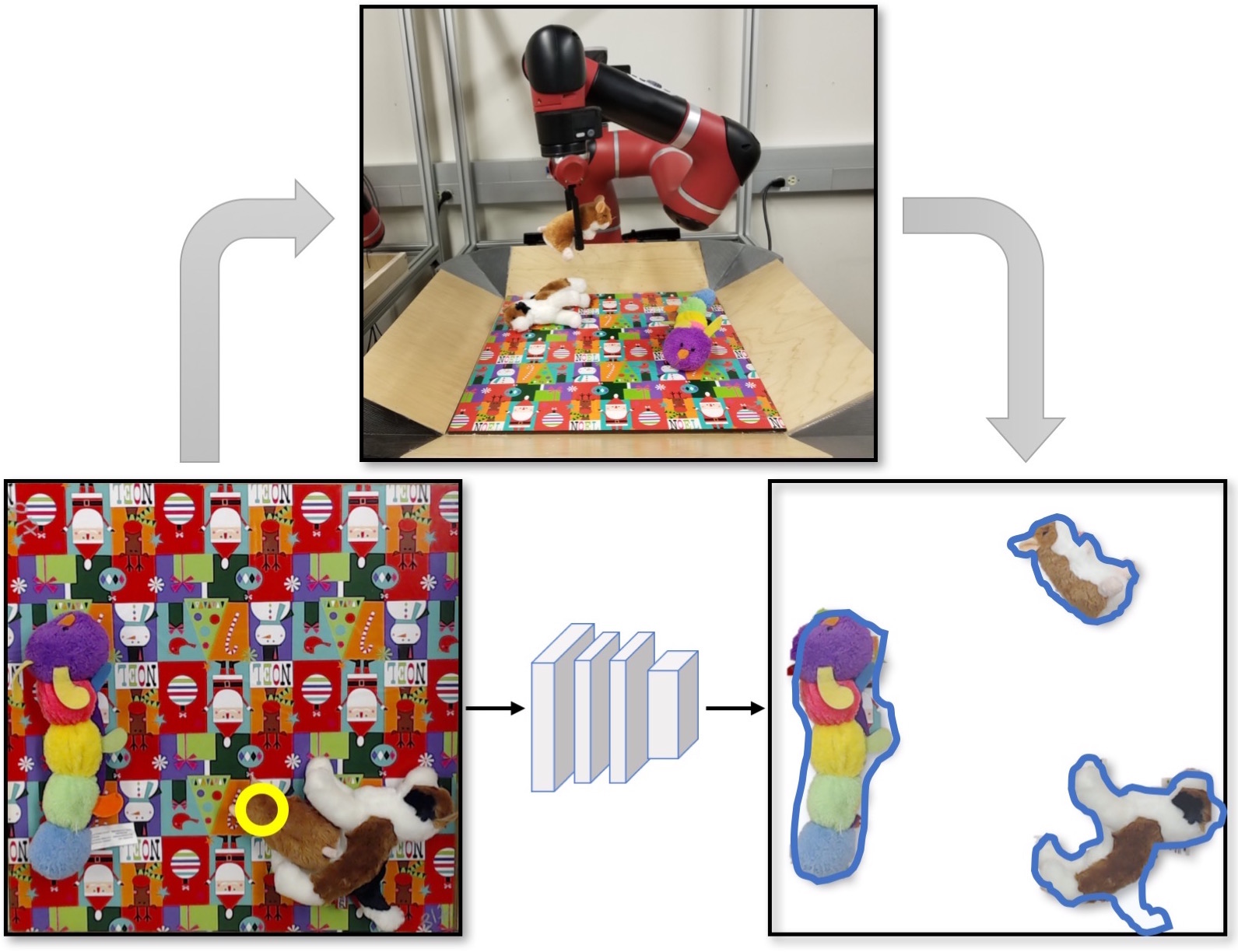
Deepak Pathak*, Fred Shentu*, Dian Chen*, Pulkit Agrawal*, Trevor Darrell, Sergey Levine, Jitendra Malik (*equal contribution) Robotics Vision Workshop, Conference on Computer Vision and Pattern Recognition (CVPR), 2018 website / arxiv We present a robotic system that learns to segment its visual observations into individual objects by experimenting with its environment in a completely self-supervised manner. Our system is at par with the state-of-art instance segmentation algorithm trained with strong supervision. |
|
Deepak Pathak*, Parsa Mahmoudieh*, Michael Luo*, Pulkit Agrawal*, Dian Chen, Fred Shentu, Evan Shelhamer, Jitendra Malik, Alexei Efros, Trevor Darrell (*equal contribution) (Oral Presentation) International Conference on Learning Representation (ICLR), 2018 website / arxiv We present a novel skill policy architecture and dynamics consistency loss which extend visual imitation to more complex environments while improving robustness. Experiments results are shown in a robot knot tying task and a first-person visual navigation task. |

|
Ashvin Nair*, Dian Chen*, Pulkit Agrawal*, Phillip Isola, Jitendra Malik, Pieter Abbeel, Sergey Levine (*equal contribution) IEEE International Conference on Robotics and Automation (ICRA), 2017 website / arxiv We present a system where a robot takes as input a sequence of images of a human manipulating a rope from an initial to goal configuration, and outputs a sequence of actions that can reproduce the human demonstration, using only monocular images as input. |
|
|
|
CS394D - Deep Learning - Fall 2020 Teaching Assistant |
|
CS395T - Deep Learning Seminar - Fall 2019 Teaching Assistant |
|
CS342 - Neural Networks - Fall 2018 Teaching Assistant |
|
|
|
IROS, ICRA, ICLR, NeurIPS, CVPR, ICML, ECCV Conference Reviewer |
|
RA-L, TPAMI, TIP Journal Reviewer |
|
|